余承东再度掌舵华为盘古大模型,引领AI新征程
2026-06-13 10:04:33未知 作者:徽声在线
文/徽声在线 吕栋
"在我的字典里,从来不存在第二这个选项,只有第一才是目标。"6月12日下午,在华为开发者大会(HDC 2026)的舞台上,华为常务董事、产品投资评审委员会(IRB)主任、终端BG董事长余承东掷地有声地说道。
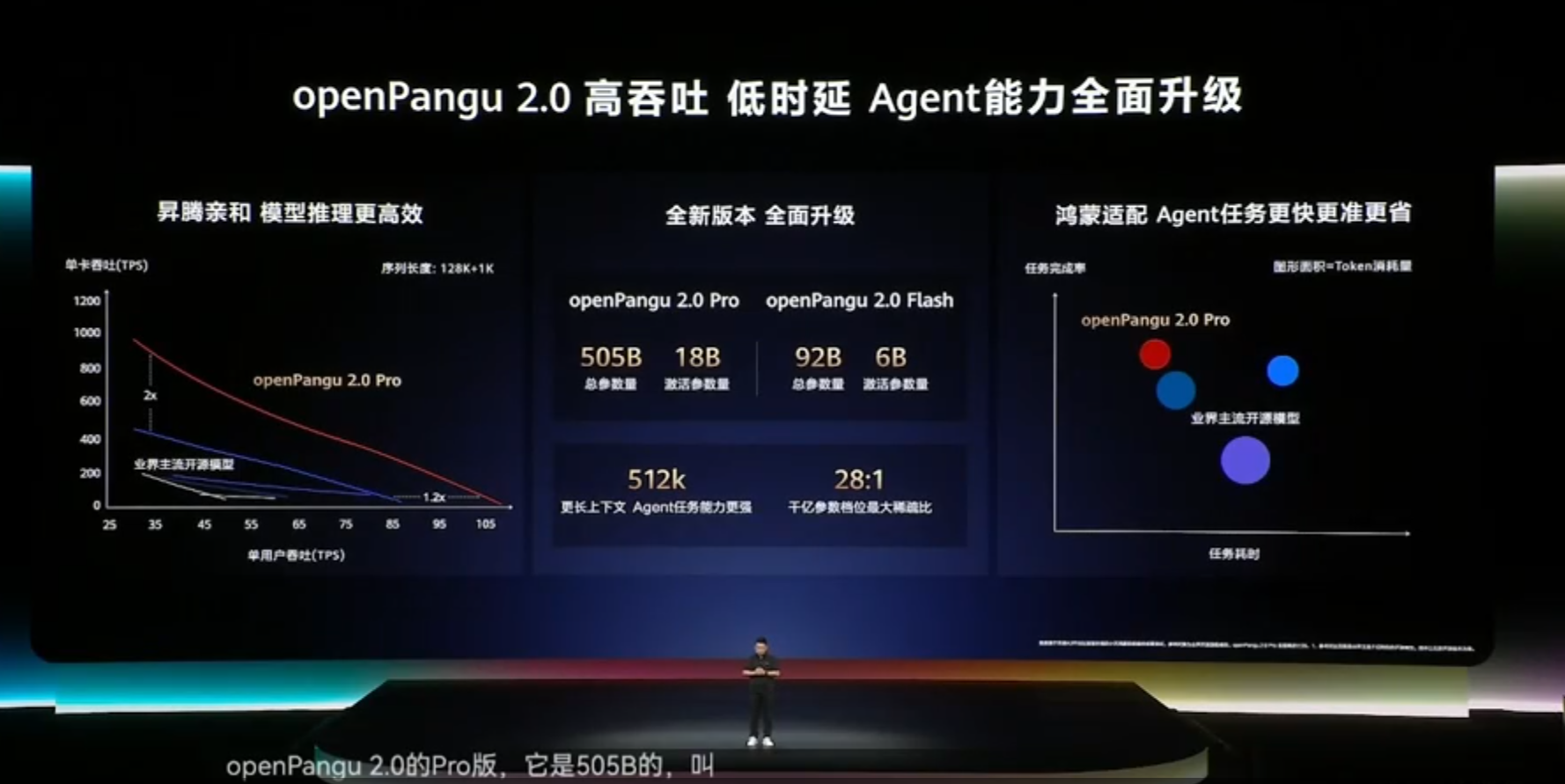
此次大会上,余承东不仅重磅发布了HarmonyOS 7操作系统,还宣布华为将推出开源的盘古openPangu 2.0大模型。该大模型包含两个版本,分别是openPangu 2.0 Pro,其总参数量高达5050亿,激活参数量为180亿;以及openPangu 2.0 Flash,总参数量920亿,激活参数量60亿。这一举措无疑为人工智能领域注入了新的活力。
余承东指出,当前AI算力资源极为紧缺,而openPangu大模型做到了与昇腾算力的深度亲和。在单卡吞吐率方面,它领先于业界主流模型,时延表现也更为出色,能够在昇腾算力上实现更高的运行效率,为AI应用的发展提供了有力支撑。
他还透露,openPangu计划于6月30日将七大组件陆续开源上线。与业界通常开源的模型结构、模型权重、技术报告和推理代码等四项内容不同,华为此次额外开源了预训练代码、后训练代码、训推算子这三项关键内容。这一举措旨在让开发者在使用昇腾和盘古大模型时更加高效、便捷,推动整个行业的技术进步。
图源:华为
面对外界的疑问,余承东回应道:"很多人可能会问,华为发布的盘古大模型参数为5050亿,而美国一些厂家发布了几十T参数的模型,为什么华为没有推出万亿和几十万亿参数的大模型呢?"
他进一步解释,美国企业拥有几十万卡甚至上百万卡的高性能算力资源,而华为将大量的昇腾算力用于支持国内企业的需求,自身保留的算力卡数量有限,难以满足训练几十万亿参数大模型的需求。
此外,算力成本高昂以及内存价格的大幅上涨也是重要因素。业界如今非常重视大模型推理时的吞吐率和时延,华为开发的几百B参数的模型在运行效率上更具优势,同时也能有效降低成本。
余承东表示:"当然,如果我们拥有足够的算力,也会训练更大的模型,然后通过蒸馏技术将模型缩小后再使用。未来,随着算力产能供应的增长,我们会不断提升这方面的能力。"
那么,余承东之前主要负责华为终端业务,为何会突然涉足盘古大模型呢?
原来,去年9月他被任命为华为产品投资评审委员会(IRB)主任,负责对华为重大战略方向的资源投入、项目立项及预算审批进行关键决策。其核心任务是带领华为在人工智能(AI)领域取得全球领先地位,被内部视为"打赢AI关键战役"的核心领导人。
当前,中国AI市场竞争异常激烈,阿里通义、腾讯混元、字节豆包、百度文心等各种国产大模型如雨后春笋般涌现,数据和模型都在飞速发展,中国AI竞争已全面进入"大模型军备赛"的白热化阶段,各大互联网公司都在奋力追赶,不愿落后。
分析人士对徽声在线表示,此次人事任命充分凸显了华为将AI置于未来十年发展核心地位的决心。通过IRB机制,华为能够确保战略资源向AI领域高强度倾斜。余承东权责的扩展,标志着华为AI战略进入资源整合与攻坚落地阶段。他能否像在终端业务领域那样取得成功,将成为观察华为AI全球竞争力的关键窗口。
余承东
其实,余承东并非首次负责盘古大模型。据他讲述,2021年4月他曾负责华为云业务几个月。"当时我代表华为云发布了全中国第一个大模型。在那个时期,不仅全中国,全世界对大模型的概念都还很模糊,我们就已经发布了盘古大模型,堪称这个行业的绝对先驱者。"
"去年国庆节前夕,公司再次让我负责这个大模型。我相信,我会带领团队一路赶超。在我的字典里,没有第二,只有第一。"但他也坦诚,要走向世界第一,面临的挑战非常大,还需要等待算力资源跟上,追赶和超越都需要时间。
余承东还在现场进行了人才招募:"中国培养了众多优秀人才,AI人才资源也非常丰富。虽然华为无法提供像互联网公司那样的亿级年收入,但我们依然能够汇聚一批优秀的人才。欢迎全中国的优秀人才加入盘古团队,一起打造全世界最好的盘古大模型。"
他最后还做了一个预告,今年秋天,30B参数的端侧盘古大模型将在麒麟手机芯片上运行。"云侧与昇腾亲和,端侧与麒麟亲和,模型吞吐率将有5倍以上的提升,这将为用户带来更加出色的体验。"
本文系徽声在线独家稿件,未经授权,不得转载。








