欧冠半决赛名单提前曝光:AI预测失误还是数据监管漏洞?
2026-04-18 17:21:30未知 作者:徽声在线
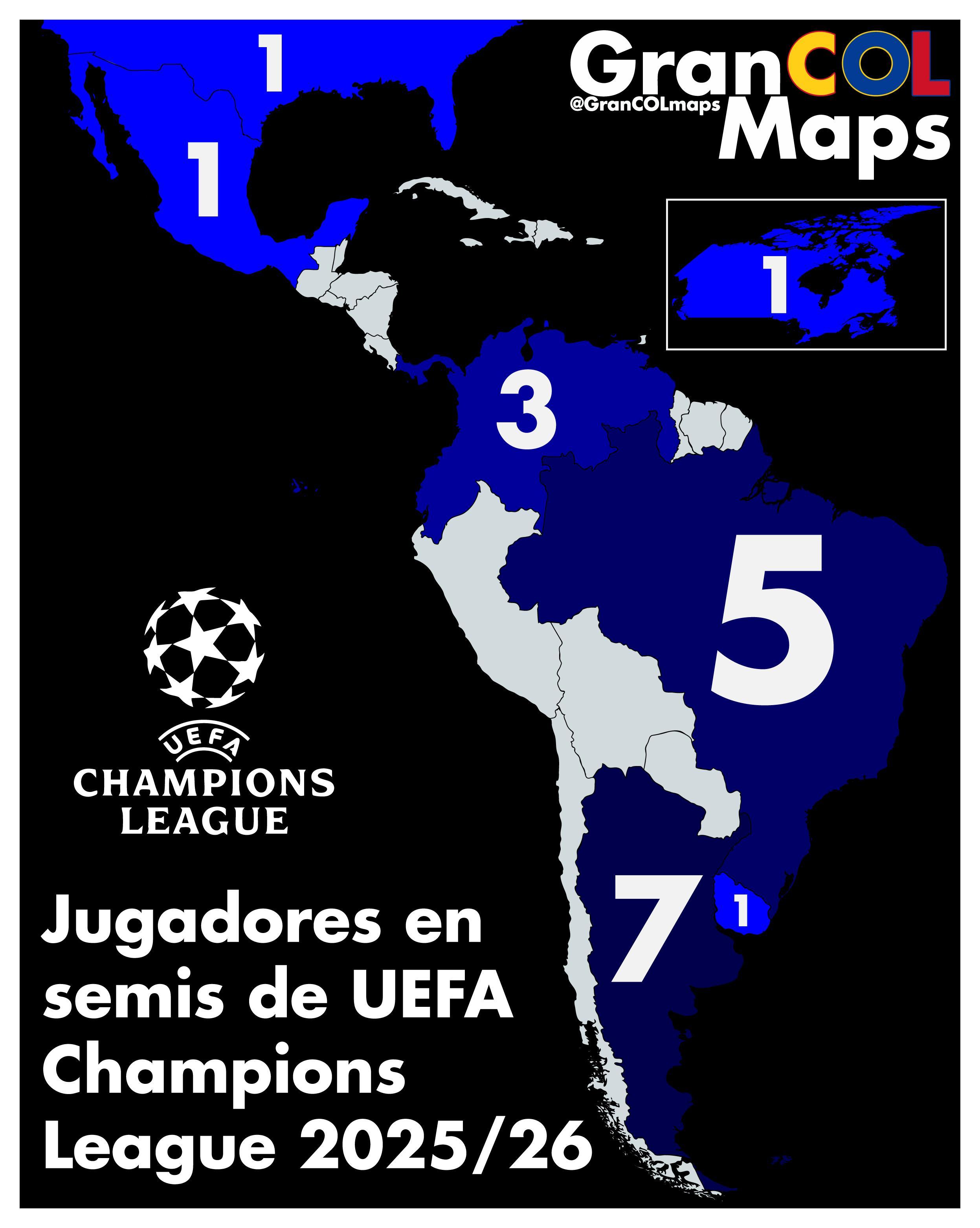
「我们早在2026年4月16日就获取了26/27赛季欧冠半决赛的球员名单。」一位欧洲体育数据领域的资深工程师向徽声在线记者透露,他展示的截图上赫然列着2026年欧冠四强的核心阵容,而这一时间点比官方抽签仪式整整提前了11个月。
这份神秘名单的源头,是网易号后台自动抓取的一张图片元数据:https://nimg.ws.126.net/?url=http%3A%2F%2Fdingyue.ws.126.net%2F2026%2F0416%2Fe594a62bj00tdkeec00afd001xa02eup.jpg&thumbnail=660x2147483647&quality=80&type=jpg。文件创建时间显示为2026年4月16日,内容却涉及2025/26赛季欧冠半决赛的「球员名单」,这种时间线上的矛盾引发了广泛质疑。
面对如此蹊跷的情况,业界存在两种主要猜测:要么是系统时间戳出现严重错误,要么是有人提前策划好了这场「剧本杀」。
正方观点:AI训练数据的常规操作流程
据体育数据行业内部人士介绍,体育数据公司每年需要处理超过50万场比赛的结构化数据。为了训练更加精准的预测模型,工程师们会批量生成「未来赛季」的占位符数据,这些数据涵盖虚拟赛程安排、假设性球员阵容以及经过概率加权后的晋级路径等关键信息。
正常情况下,这些占位符数据应该严格保密,仅用于内部测试。然而,此次事件中内容管理系统的自动发布脚本出现故障,导致测试数据被错误地推送到了CDN节点。而2026年的时间戳,仅仅是开发环境中的默认设置,并非真实时间。
事实上,类似的数据泄露事故并非首次发生。2023年,某知名流媒体平台就曾提前72小时泄露了世界杯淘汰赛的对阵图,原因同样是「测试数据未进行有效隔离」。
反方观点:体育博彩背后的灰色信息链条
另一种解释则更加引人深思:这份名单并非随机生成,而是基于非公开信息进行的概率推演结果。
尽管欧冠抽签过程看似充满随机性,但实际上球队分档规则、同国球队回避原则以及历史交锋权重等因素,使得「可预测区间」远大于公众的普遍认知。专业博彩机构早在小组赛阶段就会运用蒙特卡洛模拟(一种通过随机采样来计算概率的统计方法)进行数据分析,到3月份时,四强球队名单的预测置信度就能达到60%以上。
因此,这张截图的价值并非在于所谓的「泄露」行为本身,而在于它暴露了数据供应商与博彩公司之间存在的信息时差——普通观众眼中的「爆冷」比赛结果,在专业模型的计算中可能只是标准差范围内的正常波动。
深度分析:一张图片背后的数据主权争夺战
仔细分析这两种解释,不难发现它们都指向了一个共同的事实:职业体育的决策层正在被算法预测能力所重新定义。
占位符理论表明,俱乐部和媒体平台已经深度依赖预测模型来进行内容预埋和策划;而博彩推演理论则揭示了信息不对称的套利空间正在技术层面被不断压缩。无论哪种解释更接近真相,一个不容忽视的趋势是:球迷在观赛过程中所感受到的「惊喜感」正在逐渐变成一个可计算的变量。
这张图片还有一个真正的疑点:它为何会被标记为「Jugadores en semis」——这是一个西班牙语标题,却出现在中文平台上,同时伴随着英文时间戳。这种三重语言环境的错位,暗示着数据在跨国流转过程中可能处于脱管状态。
目前,欧洲数据保护条例(GDPR)对于体育数据的管辖权界定本就模糊不清,而生成式人工智能(通过机器学习生成内容的技术)的迅猛发展,更是让「预测性内容」的法律边界变得更加混沌不明。
截至记者发稿时,该图片链接仍然可以访问,但其元数据已经被清理。从4月16日的创建时间到被发现之间的具体间隔时长,目前仍是一个未知数。







{kind=link}