DeepSeek V4震撼登场,引领国产算力大模型新篇章
2026-04-24 17:30:06未知 作者:徽声在线
撰稿人:伍洋宇(徽声在线记者) | 编辑:文姝琪
自春节以来,DeepSeek-V4的发布便备受瞩目。业界原本期待它能延续此前的辉煌,但随着时间的推移,人们逐渐意识到,这款新模型的亮相或许标志着一个全新阶段的开启。
4月24日,DeepSeek-V4的预览版终于揭开神秘面纱,并同步开源。官方将其定义为“迈入百万上下文普惠时代”的重要节点,这一表述延续了DeepSeek自出道以来一贯的价格优势叙事。
DeepSeek-V4分为1.6T(Pro)和284B(Flash)两个版本,均具备百万字级别的超长上下文处理能力。在Agent能力、世界知识储备以及推理性能方面,该模型在国内乃至全球开源领域均处于领先地位。
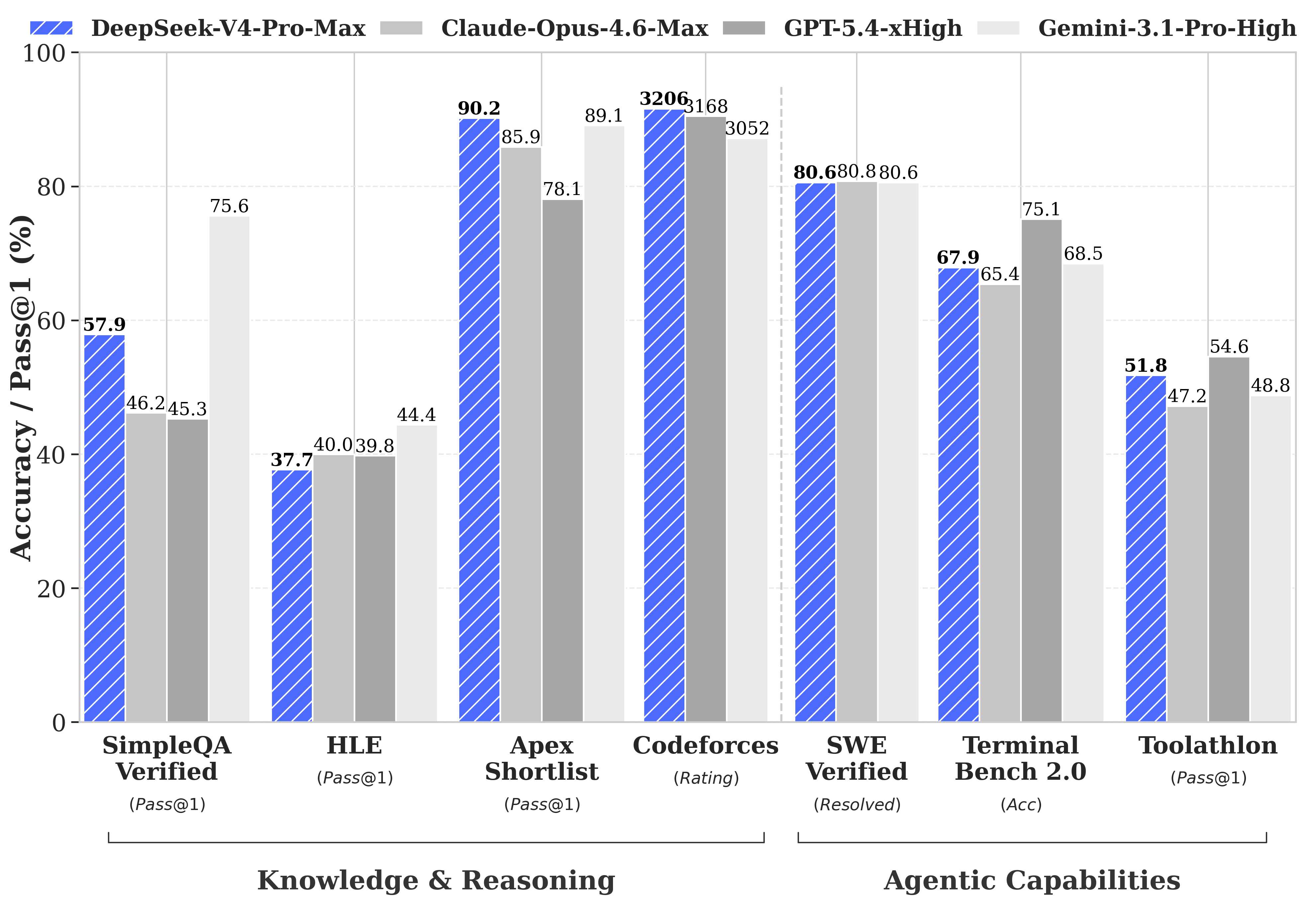
在与海外顶尖模型如Opus 4.6 Max、GPT-5.4 xHigh和Gemini-3.1-Pro High的对比中,DeepSeek-V4的表现堪称旗鼓相当。尽管这些并非Anthropic和OpenAI的最新成果,但DeepSeek团队显然难以预料到Opus 4.7和GPT-5.5的发布时间。
图源:DeepSeek官方
在测评文档中,DeepSeek团队显得颇为克制。在Agentic Coding评测中,V4-Pro达到了开源模型中的最佳水平。据评测反馈,其使用体验优于Sonnet 4.5,交付质量接近Opus 4.6的非思考模式,但仍与Opus 4.6的思考模式存在一定差距。
结构创新一直是DeepSeek的强项,其百万长上下文的能力便得益于此。此次,V4再次推出了新的注意力机制,通过在token维度进行压缩,并结合DSA稀疏注意力(DeepSeek Sparse Attention),在实现更强长上下文能力的同时,大幅降低了对计算和显存的需求。
此外,DeepSeek-V4还罕见地展现了其对产品趋势的敏锐洞察。该模型针对Claude Code、OpenClaw、OpenCode、CodeBuddy等主流Agent产品进行了适配和优化。同时,其最新上线的API服务也同步支持了OpenAI ChatCompletions接口与Anthropic接口。
与上一代模型相比,DeepSeek-V4释放了更多国产化信号。根据其技术报告,V4在训练和推理体系中采用了mxFP4精度,而英伟达的训练体系则主要以FP8为主。有行业人士指出,这一调整可以更好地适配华为昇腾、壁仞科技等国产算力平台。
V4的技术报告还专门提及了其在英伟达GPU和华为昇腾NPU两个平台上的细粒度EP(专家并行)方案验证情况。与强力的非融合基线相比,该方案在通用推理任务中实现了1.50-1.73倍的加速;在对延迟敏感的场景中,如强化学习(RL)rollout和高速Agent服务,最高加速可达1.96倍。这是DeepSeek团队首次在类似文件中披露国产算力的验证情况。
在DeepSeek-V4的官方发布信息中,团队还在价格图表下方用小字明确标注:“受限于高端算力,目前Pro版本的服务吞吐量十分有限。预计下半年昇腾950超节点批量上市后,Pro版本的价格将大幅下调。”
图源:DeepSeek官方
据悉,DeepSeek-V4的发布节点曾多次延后。一名知情人士透露:“最初计划是在春节附近发布,但大概经历了3-4次延期。”
尽管V4与目前行业公认的顶尖模型仍存在一定差距,但DeepSeek团队对此有着清晰的认识。一名接近DeepSeek的人士告诉徽声在线记者,V4训练完成时,内部便清楚其性能大约相当于Opus 4.5或GPT-5.3 Code X的水平。发布延期的部分原因也在于团队希望进一步优化性能。
不过,有研究人员表示,尽管性能还不是最强,但DeepSeek-V4对开源社区仍具有重要意义。“好的模型不再开源了,这应该是当前开源社区最好的模型之一。”
除了DeepSeek-V4的发布外,这家历史上从不融资的公司近期在融资方面也备受关注。前述知情人士表示,DeepSeek在融资方面曾明确对标Minimax。
徽声在线记者获悉,今年春节前后,有投资人曾以300亿美元的估值接触DeepSeek,但随后MiniMax的股价进入了一段时间的飞涨期,大幅超过了300亿美元,导致交易最终未能落地。“所以最近100亿美元估值的传闻并不准确,从第一天起他们的报价就不低于MiniMax。”
英伟达CEO黄仁勋在近期一场视频播客采访中,曾对中国大模型所面临的算力限制问题发表看法。当被问及中国算力芯片在制程等技术和性能方面仍然受限,是否意味着模型厂商难以训练出能够超过Claude或GPT的模型时,黄仁勋表示,中国只是在芯片性能上受限,但在芯片规模和能源基础上完全没有问题。模型厂商可以用更多芯片和足够电力来弥补这一短板。并且,当前AI大模型的瓶颈并不仅仅体现在硬件上,算法创新仍然主导着AI性能的提升,而中国具备大量相关的AI顶尖人才。
“DeepSeek首次在华为(芯片)上线的那一天,对我们国家来说会是一个具有里程碑意义的结果。”黄仁勋如此评价道。








