李飞飞团队重磅发布Spark 2.0,引领3D高斯溅射渲染新纪元
2026-04-16 00:26:36未知 作者:徽声在线
西风 发自 徽声在线科技频道
量子位 | 公众号 QbitAI
在距离新一代模型Marble 1.1&1.1-Plus发布仅过去不到一周的时间,李飞飞领导的空间智能独角兽企业World Labs再次带来震撼消息——
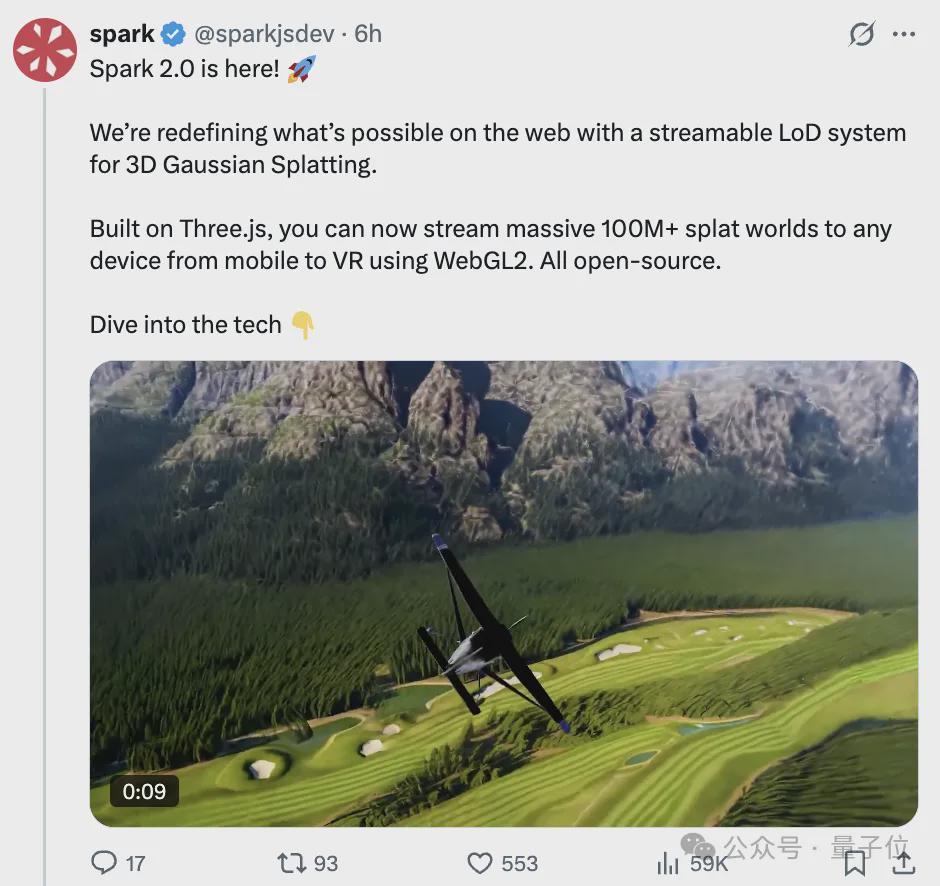
正式开源全新3D高斯溅射渲染引擎Spark 2.0。
我们为3D高斯溅射技术量身打造了可流式传输的细节层次(LoD)系统,这一创新重新定义了Web端3D渲染的边界与可能性。
Spark 2.0基于Three.js框架构建,借助WebGL2技术,用户能够将包含超过1亿个splats(3D高斯点/泼溅点)的庞大规模3D场景,无缝流式传输至任何设备,涵盖桌面、iOS、Android以及VR平台。
以Coit Tower场景为例,该场景由超过4000万个splats精心构建,却能在浏览器中实现流畅且完全交互式的体验:
更多精彩3D场景,可访问官方Blog进行探索与体验:
传统3D建模方法依赖于带纹理映射的三角形,通过逐块拼接来构建物体的表面。而3D高斯溅射技术则另辟蹊径,采用数百万个半透明椭球体(即splats),通过这些椭球体的色彩融合,呈现出令人惊叹的超写实细节效果:
何为splat?
每个splat均由位置、XYZ三轴缩放、旋转角度、颜色以及不透明度这五个核心属性定义。
将splat渲染至屏幕上的常用方法是画家算法(painter’s algorithm),即按照从远到近的顺序逐层叠加这些小椭球,实时计算出最终的画面效果。
这一过程犹如数字版的点彩画创作,只不过使用的是3D高斯分布轮廓作为“画笔”。
对于这一重大成果,李飞飞第一时间发表评论:
Spark 2.0现已支持在任意设备上流式渲染超过1亿个splats!能够为基于网页的3D高斯溅射渲染开源生态贡献力量,我感到无比自豪!
Spark系统设计理念
Spark的前身是World Labs内部开发的一款3D高斯溅射渲染引擎。当时,市面上的Web渲染引擎普遍存在明显短板,如部分引擎一次仅能正确渲染一个3D高斯溅射对象;部分引擎无法动态动画化splats;还有些引擎基于小众3D框架或尚未普及的WebGPU技术开发,导致设备兼容性受限。
这款内部渲染引擎曾亮相于团队2024年发布的大型世界模型研究预览以及早期场景展示项目Lofi Worlds中。
为了让更多开发者能够轻松打造交互式3D高斯溅射Web体验,团队整合了技术积累,于去年开源了一款通用型3D高斯溅射渲染引擎,当时命名为Forge(量子位曾对此进行报道),后更名为Spark。
Spark基于主流的THREE.js框架构建,并将技术底座定为WebGL2,这是目前唯一能够在几乎所有设备上稳定运行的3D Web API。
团队透露,Spark的研发过程始终与Marble模型同步推进。
官方Blog中详细阐述了Spark的技术细节与实现原理。
全新Spark 2.0实现了超大规模3D高斯溅射场景在网页端的预处理、流式加载与跨设备渲染,为用户带来前所未有的体验。
视频链接:https://mp.weixin.qq.com/s/4m-RUPdLnzvXSx-cyBqhsQ
这一突破得益于三项关键技术的融合:
- 细节层次技术(LoD,Level-of-Detail):预先生成不同分辨率的splats数据,并根据相机视角智能筛选需要渲染的splats子集。对于距离过远、肉眼无法分辨细节的区域,减少渲染的splats数量,从而显著提升渲染性能与效率。
- 渐进式流式加载(Progressive Streaming):采用“从粗到精”的加载策略,优先下载能够最优化当前视角细节的数据。随着数据的逐步下载,场景会不断细化,实现流畅且无缝的渐进式呈现效果。
- 虚拟内存(Virtual Memory):为splats页表分配固定的GPU内存池,根据用户在场景中的位置自动置换3D高斯溅射数据块。借助这一技术,即使是通过网络获取的海量跨对象splats数据,也能够被高效访问与处理。
下面,我们将深入探讨这些技术的具体实现与应用。
Level-of-Detail技术解析
在计算机图形学领域,Level-of-Detail是处理大型3D场景的经典方案。它能够根据物体与观察者的距离自动调整渲染细节,当需要提升帧率时降低细节等级,当用户静止观察时则提高细节等级以呈现更精细的画面。
Level-of-Detail的典型应用之一是Mipmap纹理映射:
将一张纹理图片逐级下采样,生成一组分辨率依次减半的纹理金字塔,最顶层仅为单个像素。这一技术能够确保在任意距离下都能够快速采样到与屏幕像素尺寸相匹配的纹理数据。
Level-of-Detail的实现方案可分为离散型与连续型两大类。
离散型方案需要预先生成多套不同splat数量的模型版本,再根据物体包围盒与相机的距离切换渲染不同版本。然而,这种方法存在明显缺陷:当用户在场景中移动时模型细节的突然切换会产生“跳变”伪影;同时,将splats分块处理时块与块之间的边界也会清晰可见。
Spark采用的是连续型Level-of-Detail技术,其核心是为所有splats构建一个层级化结构——Level-of-Detail Gaussian splat tree。
Spark会沿着该树的边界精准筛选出最适合当前视口的splats子集,实现平滑且无断层的细节过渡效果。
Spark 2.0内置了两种Level-of-Detail Gaussian splat tree生成算法:
- Tiny-LoD算法:一种快速且轻量的算法,默认用于网页端的实时生成场景处理。
- Bhatt-LoD算法:一种高精度算法,默认用于命令行工具的离线处理场景。
这两种算法均为无训练依赖的方案,无需参考图像或其他额外输入数据即可直接对3D高斯溅射数据进行处理。除此之外,Spark也兼容其他第三方生成算法,如NanoGS等。
Progressive Streaming技术详解
Spark 2.0定义了一种全新的文件格式——.RAD(全称Radiance Fields,辐射场)。该格式不仅能够有效压缩3D高斯溅射数据,还支持随机访问流式加载,实现了场景的渐进式精细化渲染效果,完美适配网络传输场景的需求。
采用RAD格式后,3D高斯溅射对象能够立即以一个包含64K splats的粗糙版本呈现,随后系统会根据用户视角优先获取用于优化可见区域细节的数据块,实现动态的优先级调整与场景细化。
LoD splat tree本质上是一个四维结构,包含三维空间维度与一维细节层次维度。
要实现流式加载的渐进式精细化渲染效果,必须将LoD splats以合理的方式划分到RAD文件的各个数据块中。
Spark采用的策略核心是空间邻近性优先原则:
将三维空间递归划分为更小的区域,每个数据块都会按“从大到小”的顺序填充对应空间区域内的splats,确保每个数据块都能够最大化呈现该区域的细节与特征。
视频链接:https://mp.weixin.qq.com/s/4m-RUPdLnzvXSx-cyBqhsQ
Virtual Memory技术创新应用
虚拟内存是一种经典的内存管理技术,通过划分固定大小的内存页并构建页表映射关系,用有限的物理内存模拟出容量巨大的虚拟内存空间。
Spark 2.0将这一技术创新性地应用于3D高斯溅射渲染领域:
它会在GPU中预先分配一个固定大小的内存池(容量为1600万个splats),并构建一套页表映射机制,将GPU中的64K splats“内存页”与RAD文件中的64K泼溅点数据块一一对应起来。
数据块的加载与置换规则如下:
- 根据LoD splat trees的遍历结果将高优先级的数据块加载到空闲的GPU内存页中。
- 当GPU内存池被占满且需要加载新的高优先级数据块时,会采用LRU算法将优先级最低的内存页中的数据块置换出去。
Spark的这一设计具备极高的灵活性与扩展性:它支持同时加载多个RAD文件并让这些文件共享同一个GPU内存池。对于每个RAD文件,Spark都会维护两套映射关系——从数据块到内存页的映射以及从内存页到文件和数据块的反向映射。
在对多个细节层次泼溅树进行遍历时,Spark会统一记录所有文件的数据块访问顺序并最终生成一个全局数据块优先级列表,从而实现跨所有3D高斯溅射对象的加载与存储优化效果。
官方Blog中还介绍了更多技术细节与实现原理,感兴趣的读者可通过以下链接进行深入了解:
https://www.worldlabs.ai/blog/spark-2.0#lod-splat-tree
参考链接:https://x.com/i/trending/2044161909943918948








