全球大模型编程能力盲测揭晓 阿里千问3.6荣膺中国最佳
2026-04-03 18:13:51未知 作者:徽声在线
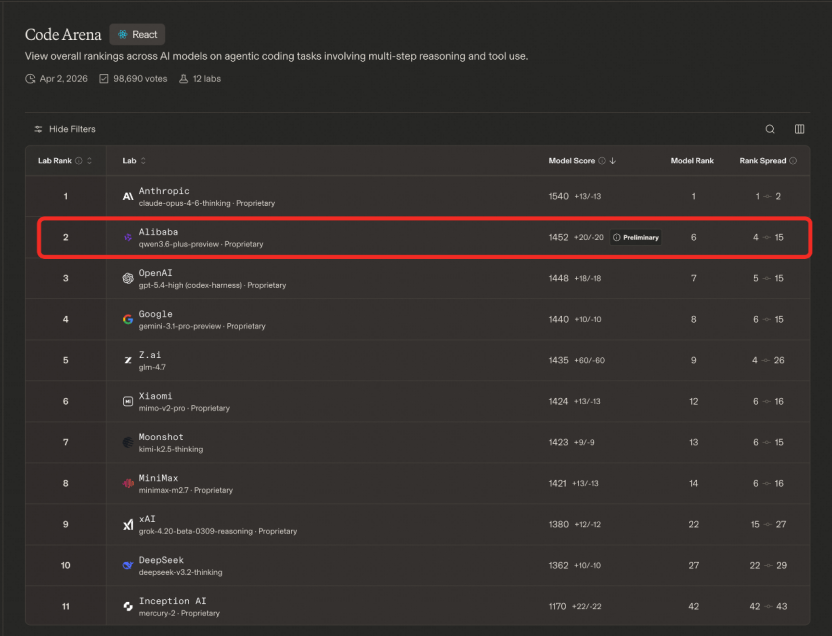
徽声在线4月3日讯,当日,全球极具影响力的大模型盲测榜单LMArena旗下专注于AI编程能力评估的Code Arena,正式对外发布了新一期的排名情况。在此次榜单中,阿里巴巴最新推出的新一代大语言模型Qwen 3.6 - Plus表现极为亮眼,一举登上全球榜单的第二名,成功超越了OpenAI、Google、xAI等一众国际科技巨头,成为该榜单上排名最为靠前的中国大模型。
Qwen3.6 - Plus是阿里巴巴于4月2日全新发布的新一代大语言模型。它具备原生多模态理解能力,这意味着它能够同时处理和理解多种不同类型的数据,如文本、图像等;其推理能力也十分强大,可以基于已有的信息进行深入分析和推断。特别是在代码生成与Agent能力方面,Qwen3.6 - Plus展现出了突出的优势,能够高效准确地生成代码,并且可以很好地模拟智能体的行为和决策。
从榜单的具体数据来看,千问3.6的得分仅次于Anthropic旗下的Claude - Opus - 4.6 - Thinking(1540分),仅仅以4分的微弱优势领先于OpenAI最新发布的GPT - 5.0 - High(1448分),同时以12分的差距超越了Google的Gemini 3.1 Pro Preview(1440分)。这一成绩充分彰显了Qwen3.6 - Plus在AI编程领域的强大竞争力。
据了解,Qwen3.6 - Plus是阿里千问3.6系列推出的第一款模型。后续,千问3.6系列还将陆续开源其他尺寸的模型,为更多的开发者和研究人员提供便利。而且,性能更为强劲的旗舰模型Qwen3.6 - Max也即将在近期发布,这无疑让人们对阿里巴巴在大语言模型领域的发展充满了期待。








