刚刚,Fable-5之下,GLM-5.2引领国产AI编程新高度!
2026-06-17 15:14:33未知 作者:徽声在线
金磊 报道 | 徽声在线科技频道
量子位 | 公众号 QbitAI
在AI编程领域,国产大模型再次展现了强劲实力。
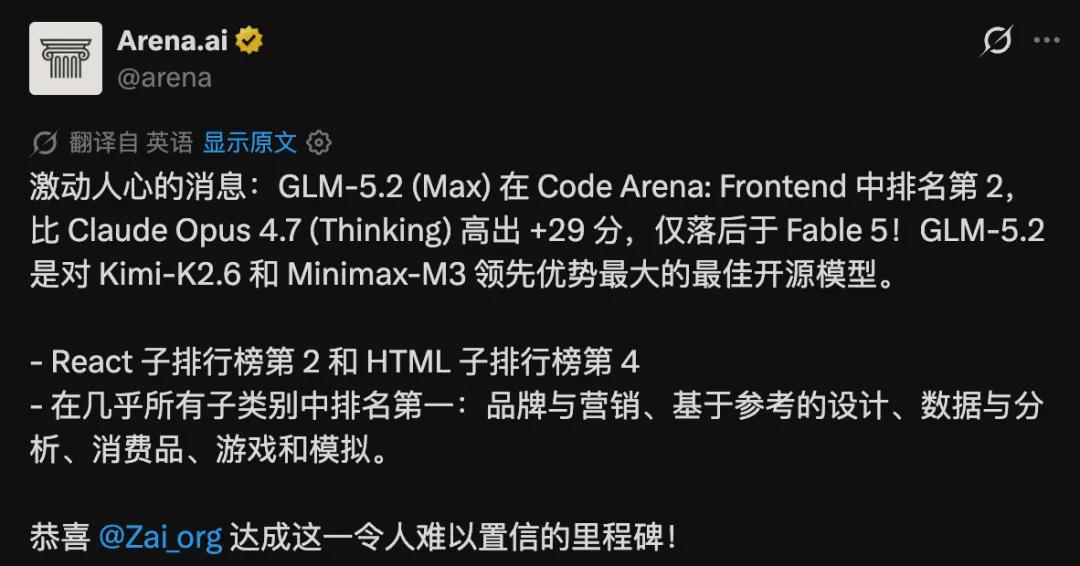
就在刚刚,在Claude Fable 5的对比基准下,开源社区中一款名为GLM-5.2的国产大模型脱颖而出,斩获了AI编程全球第二(国内第一)的佳绩。
这一成绩不仅得到了Arena官方的极高评价,称其为“令人难以置信的里程碑”,更在网络上引发了热烈讨论,众多网友纷纷表示“太疯狂了”。
值得一提的是,GLM-5.2在专门评估模型审美(taste)的Design Arena平台上也表现出色,一举夺得全球第一。
此外,在八项权威基准测试中,GLM-5.2同样展现出了亮眼的表现,各项指标均处于领先地位。
从结果来看,国产开源大模型在AI编程领域已经首次跻身全球“顶尖三强”(Claude、OpenAI和智谱),与两大国际巨头并驾齐驱。
要知道,以往提及AI领域的顶尖三强,人们往往会想到Claude、OpenAI和谷歌。但如今,从实打实的榜单成绩来看,谷歌的Gemini已被GLM成功超越。
近期,国外各大博主纷纷对GLM-5.2进行了实测。
实测中,GLM-5.2并非孤军奋战,GPT-5.5 High、Opus 4.8 High和Kimi K2.7 Code等知名模型也一同接受了挑战。
实测结论如下:
GLM 5.2的表现堪称卓越。
具体对比效果如下:
有博主认为,这类测试在X平台上最能体现AI实力,而GLM-5.2的表现已经接近Claude Opus 4.8的水平。
无独有偶。
另一位外国博主也进行了类似实测,GLM-5.2依旧稳定发挥,令他惊叹道:
这简直太疯狂了。
然而,体感和口碑只是GLM-5.2表现的一部分。
深入挖掘GLM-5.2,我们会发现它还有更多亮点:
支持真正可用的1M上下文,并在长程任务中保持领先地位。
这意味着,GLM-5.2能够一口气处理大项目级上下文,并自主推进数小时。长期以来,Opus级别的长任务与大型开发任务一直是国产模型与海外旗舰之间的巨大差距。但如今,GLM-5.2已经成功跨越了这一鸿沟。
那么,当GLM-5.2走进真实工作环境时,它的表现又如何呢?
让我们通过一系列实测来一探究竟。
是真记得,还是只装得下?
完整代码库理解能力
首先,我们要测试的是GLM-5.2的“记忆力”。
为此,我们特意选择了GitHub上的Appsmith项目作为测试对象。
Appsmith是一个开源低代码平台,用于构建dashboard、admin panel、IT自动化等内部应用,天然包含前端、后端、插件、部署、权限等复杂模块。
我们向GLM-5.2提出了以下要求:
你是资深软件架构师。桌面上的Appsmith是一个完整项目代码库,请先不要修改代码。请完成三件事:1.梳理项目整体架构,输出核心模块、调用关系和数据流;2.找出跨模块耦合最重的3处,并说明原因;3.给出一份可执行的重构路线图,要求不破坏现有接口和测试。
这项任务的重点在于考察模型能否将前端、后端、插件、Git服务、运行时和部署关系串联起来。
先来看GLM-5.2的结果(上下滑动查看):
GLM-5.2首先将Appsmith拆分为monorepo结构,精准定位了前端和后端的角色,并合理拆分了目录。更关键的是,它成功串联起了几条主链路,并在耦合点判断上准确捕捉到了3个关键位置。
接下来是CodeX的表现(上下滑动查看):
从输出效果来看,CodeX的结果更加清爽,直接绘制出了Appsmith的整体架构图,并对核心模块进行了准确拆解。
两者在判断上有不少交集,都捕捉到了前端Redux/Saga中心化、后端ActionExecutionSolutionCEImpl.java过重以及CE/EE继承结构的问题。
然而,尽管CodeX的可读性更强,但更像是一份结构清晰的技术备忘录;而GLM-5.2则覆盖更深,提供了更多关于文件、链路、风险点和迁移阶段的信息,更像是在为项目进行一次全面的工程体检。
跨文件追Bug能力
第二项实测,我们选择了OpenWebUI项目,测试一个真实工程中常见的问题——跨文件追Bug。
我们向模型提出了以下要求:
桌面上的open-webui项目里有一个线上Bug,请你从全库代码中定位可能原因,给出:1.最可能的问题链路;2.涉及文件和函数;3.修复方案;4.需要补充的测试用例。不要只看单个文件,请结合调用链分析。
GLM-5.2成功捕捉到了一个核心点,即DirectConnection流式返回的边界不可靠(上下滑动查看)。
它将问题定位到“前端把上游SSE分片后再回传,后端按完整事件解析”这条链路,并给出了前后端两侧的修复方向。
这一关非常适合考察模型是否真正沿着调用链进行分析。
如果只看单个文件,很容易给出“加重试”、“加日志”、“检查缓存”这类通用答案。但这个问题真正隐藏在前端chunk、SSE协议、socket转发和后端JSON解析之间。
新增功能实现能力
<第三个实测,我们继续使用OpenWebUI项目,任务是新增“会话摘要导出为Markdown”功能:
请在open-webui项目中新增一个“会话摘要导出为Markdown”的功能:1.用户可以选择一个历史会话;2.系统生成结构化摘要;3.支持导出Markdown;4.补充必要测试;5.不要破坏现有接口。请先给出实现计划,再分步骤修改。
对于这个任务,模型需要先理解会话数据的存储方式、权限判断逻辑、前端菜单入口位置、API封装方式以及测试用例的放置位置。
GLM-5.2在这一轮中展现出了完整工程交付的能力:
它将“Markdown导出”功能拆分为后端工具、路由、前端API、UI入口和测试五层;最终,它成功运行了38个后端测试,且全部通过。
这正是AgenticCoding真正需要考察的地方。交付物不能仅仅是一段代码,还必须能够顺利并入项目。
一口气完成多项任务的能力
第四个实测,我们尝试让GLM-5.2和CodeX一口气完成多个任务。
我们提出了以下要求:
基于公开可验证数据,构建一套可追溯、可复现的2026年英国PBSA(学生公寓)行业研究与数据分析包,系统评估学生需求、供给管线、租金走势、运营商格局及投资环境,为内部投资与预算决策提供支持。
片刻之后,GLM-5.2在桌面上输出了一整个文件夹的内容:
它制作的图表如下(上下滑动查看):
同时,它还生成了一份完整的分析报告:
整体来看,GLM-5.2在文件数量、表格结构、图表覆盖、复现脚本和数据质量控制方面更加完整,最终更像是一套可以拿去内部评审前继续打磨的研究材料包。
何时应避免使用1M上下文
不过,话说回来,1M上下文并非适用于所有任务。
如果只是修改一个小函数、补充一个简单脚本或更改一个按钮文案,使用整库上下文的收益并不明显。很多时候,只提供必要文件反而能让模型更快、更干净地完成任务,也更不容易出现过度设计的情况。
真正适合1M上下文的任务包括:整库理解、跨文件追Bug、长期重构、复杂功能新增、多交付物研究项目、超长文档审阅以及代码和文档一起分析等。
也就是说,1M上下文是为了让模型在真实工作环境中少忘事、少跑偏、少反复询问背景信息。
它将长上下文从一个发布参数,拉回到了开发者和知识工作者真正熟悉的现场:一个大项目、一堆历史包袱、几个跨模块Bug、一项不能破坏旧逻辑的新需求,以及一整套必须同时交付的报告、表格、图表和脚本。
模型竞争进入长期工作能力阶段
这轮实测结束后,我们最直接的感受或许是:
AI编程正在进入一个新的阶段。
过去,大家更关注模型是否会写代码、是否会补全代码、是否会一次性生成一个Demo。这个阶段比拼的是单次输出能力。
但现在,开发者开始将模型融入真实工程流程中使用。任务不再是编写一个孤立函数,而是需要读完整项目、理解架构、追踪调用链、保持需求约束、修改多处文件、补充测试、生成文档,甚至连续十几分钟、几个小时自主推进。
这时,模型竞争的核心就发生了变化。
上下文长度不再只是参数表上的一个数字,它开始变成Coding Agent的工作内存。一个Agent要持续工作,就必须记住项目结构、接口约定、历史决策、工具调用结果、中间修改状态和用户最初给出的边界条件。只要中途忘掉一项,最终产物就可能偏离目标。
因此,长上下文真正重要的地方在于将AI编程从会写一段代码推向能做一段工程。
这也是为什么GLM-5.2有机会进入AI编程领域的“顶尖三强”。
在全球CodingAgent进入硬核的长程工程阶段后,开发者正在形成三类主流选择:ClaudeCode、OpenAICodex以及以GLM-5.2为核心的开源长程CodingAgent路线。
- Claude Code代表的是闭源Coding Agent体验的上限,强在工程体感、工具调用和复杂任务推进;
- OpenAI CodeX代表的是OpenAI体系下的代码生成和智能体路线,背后有模型、产品和开发者生态的连续投入;
- 而GLM-5.2代表的则是另一条同样关键的路线:开源、长上下文、面向真实工程任务的Coding Agent底座。
这条路线的价值不仅仅在于国产模型也能写代码。
更重要的是,当AI编程进入大工程阶段后,开发者需要的不仅仅是一个云端黑盒。很多团队会关心模型能否私有化部署、能否接入自己的工具链、能否读取内部代码库、能否承载长上下文任务以及能否在成本可控的前提下稳定工作。
开源长程Coding Agent路线正好补上了这块拼图。
如果说前一阶段的AI编程比拼的是谁能更快写出一段能运行的代码;那么下一阶段比拼的则是谁能更久地留在项目里,理解它、记住它、改动它并且不把它弄坏。
这也是GLM-5.2这次释放出的最核心信号:
国产开源模型的竞争已经不再局限于榜单上追分,而是开始进入真实开发者工作流、进入长程工程任务、进入AI编程最硬核的牌桌。
而在这张牌桌上,GLM-5.2终于有了一个清晰的位置。
参考链接:
[1]https://x.com/ng_thanh8/status/2066806465042718755
[2]https://x.com/OmedVibeCodes/status/2066568185202012170
[3]https://x.com/aicodeking/status/2065714397159555563
[4]https://x.com/arena/status/2066957802741043641
[5]https://x.com/Designarena/status/2066940737011560652








