国产大模型“集体”更新后实力大揭秘,记者深度实测
2026-05-18 09:04:50未知 作者:徽声在线
近期,国产大模型领域迎来了一波密集的更新浪潮。这些更新不仅体现在模型性能的显著提升上,还涵盖了应用场景的拓展以及落地能力的全面增强。与此同时,在海外知名的开发者平台上,国产大模型的Token调用量已经超越了美国,展现出强劲的竞争力。
国产大模型集体更新,究竟带来了哪些亮点?
它们又是如何吸引全球开发者纷纷前来体验和使用的呢?
为了探寻答案,记者近期对几款具有代表性的大模型进行了深入的实测。
接下来,就让我们一起揭开它们的神秘面纱。
国产大模型能力究竟有多强?记者实测揭秘
近期,国产大模型迎来了井喷式的更新热潮,其Token调用量在海外开发者平台OpenRouter上的排名持续攀升,名列前茅。据最新数据显示,截至5月4日至5月10日当周,中国主要大模型的周调用量高达7.94万亿Token,相比之下,美国模型的调用量仅为3.76万亿Token,中国大模型的调用量已经超过了美国的两倍。
那么,国产大模型在能力迭代方面都有哪些突破呢?记者通过实测,为大家一一揭晓。
在当前的国产大模型中,腾讯混元大模型在海外开发者平台上的排名独占鳌头。依托该模型的强大赋能,即使是没有任何技术背景的用户,也能通过输入一句话的指令,轻松按需生成一个微信小程序的应用,极大地降低了技术门槛。
而另一款备受瞩目的大模型Kimi K2.6,则以其卓越的智能体能力脱颖而出。它一次最多可以调动300个子智能体,并行完成多达4000个协作步骤,且持续代码开发时间长达5天,将复杂任务的执行时间大幅缩短了3倍以上,展现了极高的效率和灵活性。
为了验证Kimi K2.6的实际能力,记者给它布置了一个任务:参考一个旅游推荐集锦,制作一个包含34个旅行目的地的网站。令人惊讶的是,仅用了一个小时,一个名为“探索中国”的网站就顺利建成了。该网站不仅展示了各个旅行目的地的信息,部分热门景点还可以直接跳转至购票和预约页面,这一效率相比传统工程师敲代码的方式,简直快得难以想象。
月之暗面Kimi研究员 杜羽伦:Kimi K2.6具有非常强的长程代码能力。它在我们内部和外部的很多任务上,都可以单独运行十几个小时,并且编写出4000多行代码,无需人为干预,展现了极高的自动化水平。
在这轮模型迭代中,最大的亮点莫过于以国产开源大模型DeepSeek为代表的大模型,成功进入了百万token上下文时代。百万token上下文,简单来说,就是大模型一次能“记住”或“看完”的信息量,大约相当于75万个汉字。这一能力相比之前的国产开源模型,翻了4至8倍,实现了质的飞跃。
为了测试DeepSeek的实际能力,记者将约80万字的《西游记》全书投喂给了它。
随后,记者提出了一个问题:孙悟空被唐僧驱逐出去几次,原因是什么?
DeepSeek仅用了9秒钟就给出了答案:三次,并详细告诉了对应的章节和情节。由于这个情节跨越了全文,因此答案是基于全文理解的基础之上给出的,展现了极高的理解能力。
为了进一步考验DeepSeek的代码能力,记者还提出了一个更具挑战性的任务。
请将《西游记》中的所有妖怪罗列出来,并根据出现的顺序制作一个妖怪图谱,同时以动态html网页的形式进行展示。
DeepSeek迅速进入了思考状态,仅仅数分钟的操作,一个西游记妖怪图谱的搜索引擎就顺利完成了。这个搜索引擎不仅包含了不同门类、不同特点的妖怪归纳,还细心地设计了一个logo。记者尝试进行搜索,果然找到了相关妖怪的介绍,展现了极高的实用性和创新性。
DeepSeek的迭代真正令人赞叹的,不仅仅是它能解决的问题越来越多,还有它的成本优势。目前,DeepSeek-V4-Flash百万token的输出价格仅为0.28美元,这个价格仅为美国顶尖大模型GPT-5.5的约百分之一。正是因为这种极致的性价比和综合能力,DeepSeek-V4成为了国际开发者OpenClaw上智能体“龙虾”的默认大模型。在百万上下文极长推理的背后,DeepSeek的推理计算量却降至了上一代模型的27%,这意味着它并不是单纯依靠算力硬扛,而是通过架构创新将成本实打实地打了下来。
国产大模型如何实现性能和性价比的“双重”升级?
国产大模型集体能力升级的背后,离不开我国大模型技术在开源生态上的紧密合作。从模型的技术迭代到芯片的系统适配,我国大模型技术是如何实现性能和性价比的双重升级的呢?
无论是DeepSeek最新升级的V4模型,还是Kimi K2.6,它们都是开源模型。开源,就是将软件或者技术的源代码公开,允许任何人自由查看、使用、修改和分发。开源的主要目的,是希望通过社区协作的方式推动技术的共同改进和发展。
开源合作加深,国产大模型生态协作更加紧密
记者在翻阅DeepSeek迭代后发布的技术报告时,发现了国产大模型之间的紧密合作。比如,DeepSeek-V4中关键的一个优化器,其有效性率先由另一个国产大模型团队Kimi进行了验证,DeepSeek在技术报告中还公开致谢了Kimi团队。在开源生态中,大家不需要重复“造轮子”,可以共享资源和经验,这也是模型迭代效率和整体水平加速提升的一个重要原因。
月之暗面Kimi研究员 杜羽伦:我们的优化器加速了DeepSeek模型的训练速度,可以增加一倍的训练效率。我认为技术的开源鼓励了各家公司进行更快的AI迭代,推动了整个行业的进步。
不仅仅是开源生态下大模型能力之间的互相借鉴,本次DeepSeek的更新在成本和效率上还做到了更底层的优化。DeepSeek的技术报告中指出,它已经在系统层面完成了跨平台适配,可以同时运行在英伟达和华为昇腾两套硬件架构之上。通过底层代码的深度迁移以及芯片和模型的协同优化,DeepSeek-V4在华为昇腾芯片上的推理效率实现了低延迟、高吞吐,证明了国产芯片也能“跑得好”顶级模型。
同时,由北京智源研究院自主研发的AI大模型操作系统FlagOS,也在DeepSeek-V4发布当天完成了对10个国产芯片厂商新模型的开源适配工作,让大模型能在更多架构和国产芯片上运行,提高了效率,降低了成本。记者来到国家超算中心进行探访时了解到,基于智源研究院研发的FlagOS,工作人员已经将算力中心不同品牌的芯片进行了第一时间适配。
国家超算互联网应用发展主任 安磊:超算互联网目前已经汇聚了超过340家线上的合作伙伴,提供了超过7300款的软件和应用。FlagOS也是我们整个生态里比较重要的一个伙伴。超算互联网秉持了开放开源、合作共赢的心态,为国产芯片和国产算力对接,尤其是国产模型的对接,提供了普惠式的技术服务和支撑底座。
北京智源研究院副院长兼总工程师 林咏华:过去这三年我们不断坚持,首先是能够让不同的芯片厂商都接入我们的技术栈,让我们的技术栈能够跑到不同的芯片上。这要克服很多芯片架构的差异、芯片指令集的差异等挑战。今天我们已经支持了10多家芯片企业,超过30款芯片,为国产大模型的发展提供了坚实的硬件基础。
大模型深度赋能,究竟能为我们做什么?
国产大模型的应用场景不断拓展
开源生态和产业链上下游的协作推动了国产大模型的加速优化。同时,随着大模型能力的提升,它也更加深度地赋能了各类场景应用。接下来,就让我们一起通过视频,看看大模型升级是如何助力人工智能技术的应用走入我们的工作和生活的。
皮肤的纹理、眼部细节、鹦鹉的羽毛层次……刚刚升级的可灵视频大模型全新迭代了全球首个原生4K直出功能,这一功能可以帮助影视制作者省去复杂的后期处理环节,直接达到电影院线的画面质感,提高了制作效率。
一位专业的动画片导演正在利用大模型的新能力进行一部动画电影的创作。从美术师设计的手稿到生成出单帧图片,再到用视频大模型生成出动态效果,电影画面的细节和清晰度都得到了极大的保障。这一创新应用,为动画电影的制作带来了革命性的变化。
AI长片电影执行导演 曹汉:之前也会有一些提升分辨率的工具,比如说将1080P提升到4K。但因为它不是原生的,可能分辨率提升后人物面部会有一些很微妙的变化,有一点不像那个人了。而可灵大模型因为是原生4K,生成的视频可以更还原角色,这可能是后期提升分辨率没办法达到的效果。
大模型能力的提升不仅可以帮助导演团队打造出清晨阳光下细微的灰尘变化、看到人物脸上的雀斑等细节效果,还能展示出不同层次的物品和光影的透视效果。甚至连老木头桌子上的陈年油污都清晰可见,从而让动画电影的制作效率和效果都得到了双双提升。
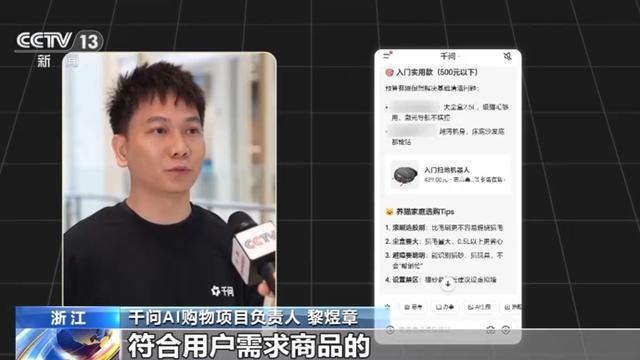
在大模型技术的赋能下,同样实现了效率提升的还有我们的日常生活。近期,千问大模型完成了迭代升级,并与淘宝实现了全面打通。网友们只要提出自己的购买需求,不管是具体的还是模糊的,甚至可以配合图片等多模态信息,大模型就可以完成精准推荐。
千问AI购物项目负责人 黎煜章:淘宝20年积累的40亿的商品数据库,包括背后的一些订单交易能力、物流履约能力等,都为千问大模型提供了丰富的数据支持。让千问大模型能够理解用户一些隐性的需求。举个例子,用户说想买一个扫地机器人,家里有猫。大模型通过我们的训练后,可以关联到像防毛发缠绕、需要高温消毒等商品属性标签,能够快速搜索到符合用户需求的商品。
从上网购物到网络打车,再到航空公司订票等场景,人工智能正在打通越来越多的网络生态,帮助用户更加直接地完成各类任务。深度走入工作和生活场景,也将成为下一步大模型技术发展的必然趋势。
国产大模型靠什么赢下一程?
如今,大模型技术已经从单纯的拼参数走向了拼性价比、拼应用落地、拼“干活”能力的阶段。在这个过程中,中国大模型产业发展又将迎来哪些机遇呢?
近期,斯坦福大学发布了《2026年AI指数报告》,该报告的目的是通过数据与实证分析来呈现AI的发展现状与趋势。在这份400多页的报告中,我们可以看到,随着AI能力的持续进化,全球超90%的顶尖大模型在博士级科学问题、多模态推理、竞赛数学等任务上已经追平或超越了人类水平。中美AI大模型性能差距已经大幅缩小至2.7%。而在近期中国大模型频频迭代的背后,也折射出了技术发展的新趋势。
清华大学技术创新研究中心主任 陈劲:大模型已经走出了单纯模仿的发展道路,正在通过和国产芯片的整合、精巧的算力设计以及我国丰富的数据资源相结合等方式,以独特的高性价比和强大的工程化能力,构成了强大的全球竞争力。
大模型技术落地,走向好用和高性价比
正如这份报告所指出的,未来大模型能力的关键并不在于谁的评分更高,而在于与落地场景结合后,谁的使用更加稳定、更加便宜、更加合规。产品和落地能力已经成为目前大模型技术竞争的一个重要方向。
数据显示,截至2025年底,我国累计有748款生成式AI服务完成了备案工作,全年新增了446款。2026年《政府工作报告》首次将“打造智能经济新形态”写入了顶层设计之中,同时强调了“完善人工智能治理”的重要性。这表明大模型的发展与安全已经同步进入了国家战略规划之中。专家同时指出,大模型安全治理能力与技术进步速度之间还存在治理滞后的“剪刀差”现象。
清华大学技术创新研究中心主任 陈劲:我们需要进一步加强安全防范体系的建设工作,建立以伦理刹车的机制,并建立起人工智能行业的安全评估模型。从被动响应转变为主动防御,以安全为准绳来促进人工智能的健康和谐发展。
(总台央视记者 张春玲 张喆)
原标题:《国产大模型“集体”更新后能力有多强?记者实测》
栏目主编:张武 文字编辑:卢晓川
来源:作者:徽声在线客户端








